Linux 下 64 位汇编语言
Linux下 64 位汇编语言学习记录。时至今日,汇编语言的重点已经不是编写汇编语言代码,而是看懂 GCC 编译器生成的汇编语言,本文正是以此为目标进行学习。
如何得到一个汇编语言模板
#include <stdio.h>
int main()
{
printf("helloworld\n");
return 0;
}对上面最经典的 C 语言入门程序使用 gcc -S main.c -o main.s ,便可得到一个汇编语言模板:
.file "main.c"
.text
.section .rodata
.LC0:
.string "helloworld"
.text
.globl main
.type main, @function
main:
.LFB0:
pushq %rbp
movq %rsp, %rbp
leaq .LC0(%rip), %rdi
call puts@PLT
movl $0, %eax
popq %rbp
ret将无用的部分去除后,就是我们需要的汇编语言框架模板:
.section .rodata
OUTPUT:
.string "helloworld"
.text
.globl main
main:
pushq %rbp
movq %rsp, %rbp
leaq OUTPUT(%rip), %rdi
call puts@PLT
movl $0, %eax
popq %rbp
ret定义数据
常用的数据类型:
.ascii # 文本字符串
.asciz
.string
.byte
.double
.float
.int
.long # 4 字节整型
.octa # 16 字节整型
.quad # 8 字节整型
.short # 2 字节整型定义方法:
.section .rodata
OUTPUT:
.string "helloworld"
PI:
.double 3.1415926 # 定义 double 类型
SIZES:
.long 100, 500, 235定义常量:
.section .rodata
.equ LINUX_SYS_CALL, 0x80 # 定义常量
main:
movq $LINUX_SYS_CALL, %rax # 使用常量定义未初始化变量:
.comm # 声明未初始化的数据的通用内存区域
.lcomm # 声明未初始化的数据的本地通用内存区域.section .bss
.lcomm buffer, 10000 ; 只是声明,不占用硬盘空间
.section .data
MY_BUFFER:
.fill 10000 ; 填充 10000 字节,占用了磁盘空间传送数据元素
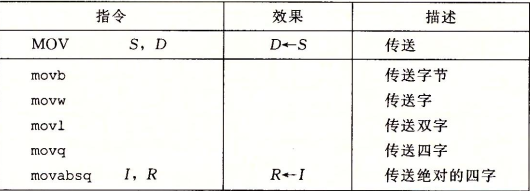
内存寻址模式:
base_address( offset, index, size ) # 格式
base_address + offset + index * size # 所表示的地址.section .data
value:
.int 123
store:
.int 0
main:
movl value, %eax # 内存 => 寄存器
movl %eax, store # 寄存器 => 内存数组示范:
values:
.int 10, 15, 20, 25, 30, 35, 40
main:
movl $3, %edi
movl values( , %edi, 4 ), %eax # 将 values + 3 * 4 处的值(25)传送给 eax间接寻址:
movl values, %eax # 将 values 地址处存储的值(10) 传送给 eax
movl $values, %ebx # 将 values 地址本身 传送给 ebxmovl $output, %edi # 将 output 地址本身传送给 edi
movl %eax, %ebx # 将 eax 的值传送给 ebx
movl %eax, (%edi) # 将 eax 的值传送给 edi 存储的内存地址处( 即output处 )对寄存器中内存地址进行偏移操作:
store:
.int 0
values:
.int 12, 13, 14, 15, 16,17
movl $values, %edi
movl %eax, 4( %edi ) # 将 eax 的值传送到 value + 4 内存地址处( 13 所在位置)
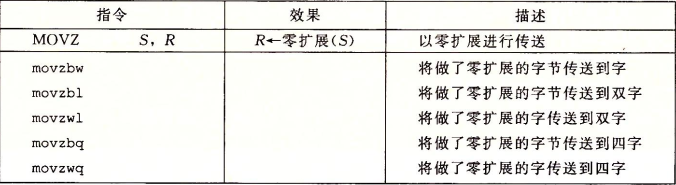
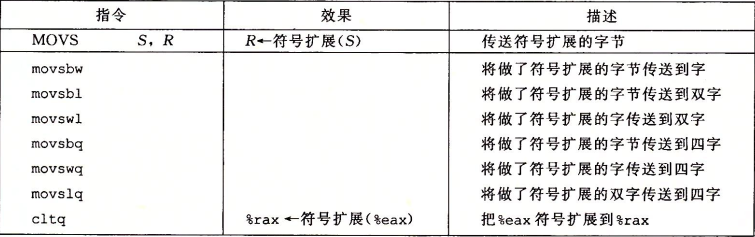
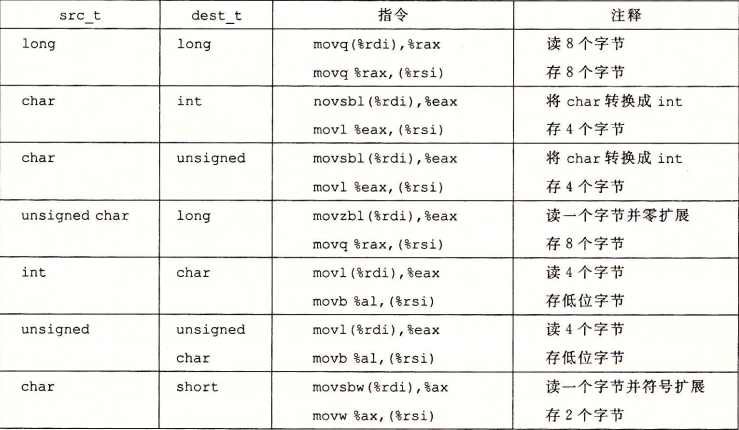
movl %ebx, -4( %edi ) # 将 eax 的值传送到 value - 4 内存地址处( store 所在位置)对于从较小的源传送到较大的目的地时,有两种类型的指令: 零拓展MOVZ 与 符号拓展MOVS:
栈操作

算术和逻辑操作
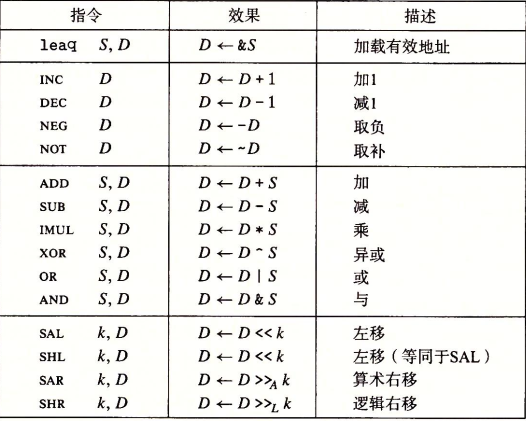
位移例子:

ps:只有最低位的字节才指示着位移量,所以是%cl。
特殊的算术操作

对于乘法: 其中一个乘数固定为rax,另一个乘数则是mulq的操作数 而得到的乘积,低位 8 字节存于rax,高位 8 字节存于rdx,下图为 64 位乘法实现的汇编代码:

对于除法: 被除数放在rdx(高 64 位)rax(低 64 位)中,rax设置好后,rdx不需要人工赋值,而是通过cqto指令自动读出rax的符号位,然后设置到rdx的所有位; 除数则是idivq的操作数;除完后,商被保存在rax中,余数则保存在rdx中。下图是 64 位有符号数除法的实现:

对于无符号 64 位除法,则只需要将rdx强制设置为0,指令改用divq 即可:

条件测试指令

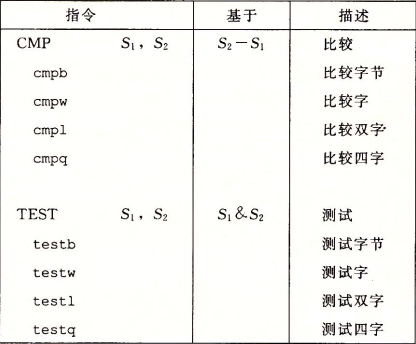
比较和测试指令只设置标志位,不改变任何寄存器的值。所以常常配合set指令使用:

# 函数 long comp( long a, long b ){ return a < b; }
comp:
cmpq %rsi, %rdi # 比较 S1 与 S2, 实际执行 S = S2 - S1, 然后根据 S 的情况设置标志位
setl %al # 根据标志位 SF ^ OF 的值,设置 al 为 0 或 1
movzbl %al,%rax # 将 rax 的高位全部清零
ret # 返回给外部值为 0 或 1 (rax)
# 函数 long test( long a ) { return a > 0; }
test:
testq %rdi, %rdi # a & a , 结果还是 a, 根据 a 的情况设置标志位
setg %al # 根据 ~( SF ^ OF ) & ~ZF 设置 al 为 0 或 1
movzbl %al, %rax # 将 rax 的高位全部清零
ret # 返回给外部值为 0 或 1 (rax)条件跳转指令
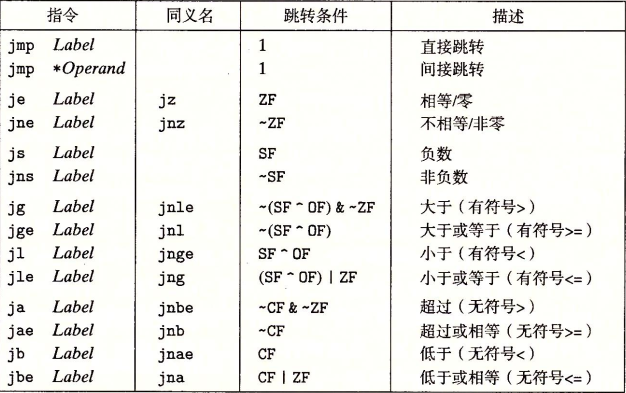
条件跳转例子:

条件传送指令
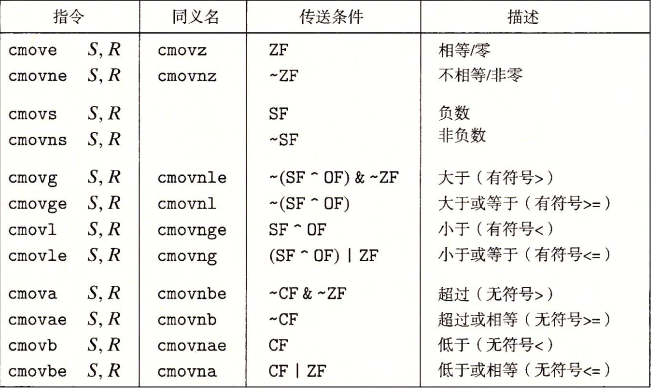
条件跳转指令在现代处理器上,可能会非常低效(30 周期),所以人们开发了一种数据的条件传送指令(1 周期)作为替代。基本思想是:计算一个条件操作的两种结果,然后再根据条件是否满足从中选取一个结果传送。
使用-Og编译出的代码还在使用条件跳转指令:

而使用-O1编译出的代码已经使用了条件传送指令:
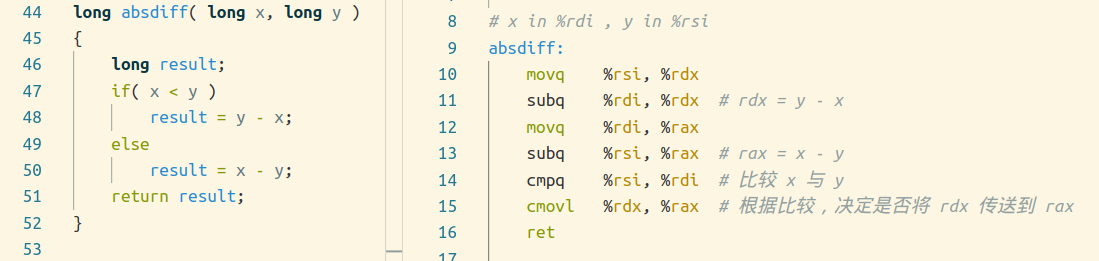
C 语言循环
从汇编语言代码反推 C 语言代码
找到 C 程序变量和寄存器之间的映射关系
由于编译器常常会优化计算,所以可能有些 C 变量在汇编里已经没有对应的值了
编译器也会引入 C 代码中不存在的新值用于优化
编译器还常常试图将多个程序变量都对应到一个寄存器上,重复利用,以达到最小化寄存器使用率的目的
do-while 循环
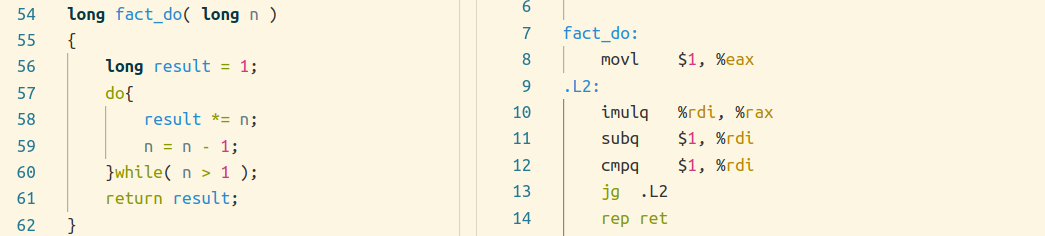
while 循环
第一种编译方法是跳转到中间,使用-Og时采用:
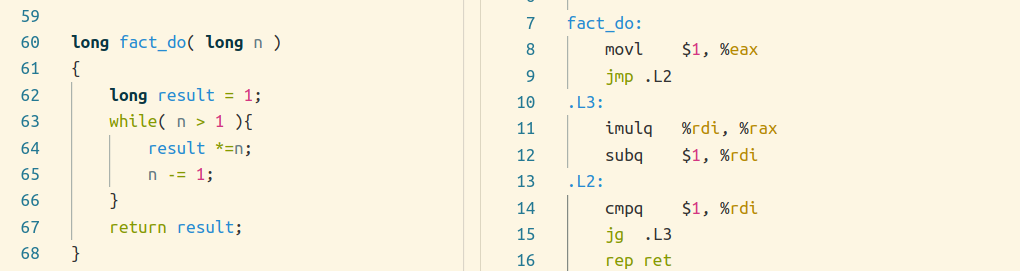
第二种是首先判断初始条件,不满足就跳过循环,然后当作do-while循环去编译,使用-O1编译时采用:
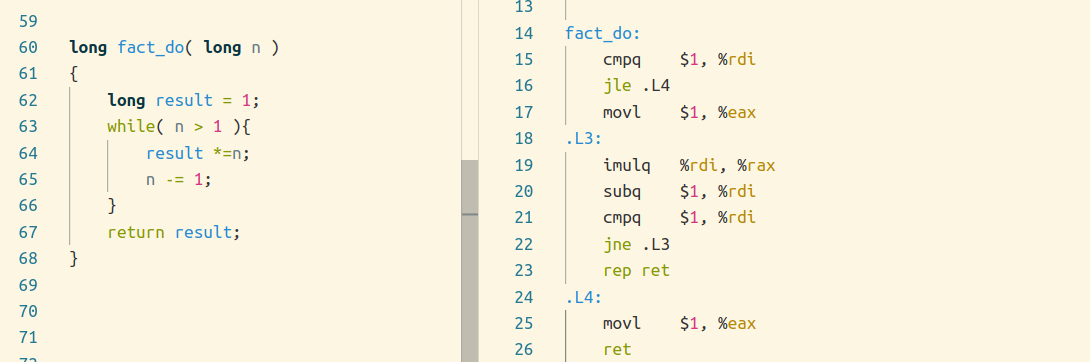
for 循环
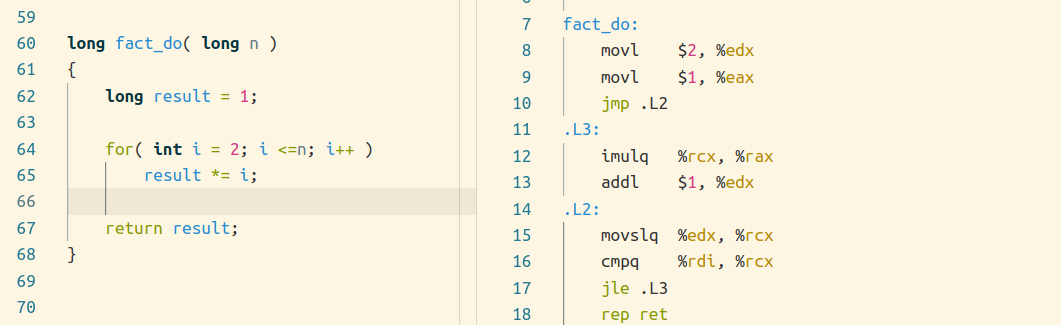
通过上图可知,for循环只是 C 语言中while循环的一种变体写法。
switch

switch 中,编译器使用了一种跳转表的技术,当case的所有值在一个范围内时,会使用这种编译优化。
函数实现 运行时栈

函数是很重要的一种抽象,它提供了一种封装代码的方式,用一组指定的参数和一个可选的返回值实现了某种功能。
假设P调用函数Q,执行完毕后返回到P,这个过程需要的机制如下:

一个通用的运行时栈如下,它的功能有:传递参数、存储返回信息、保存寄存器,以及局部数据的存储:
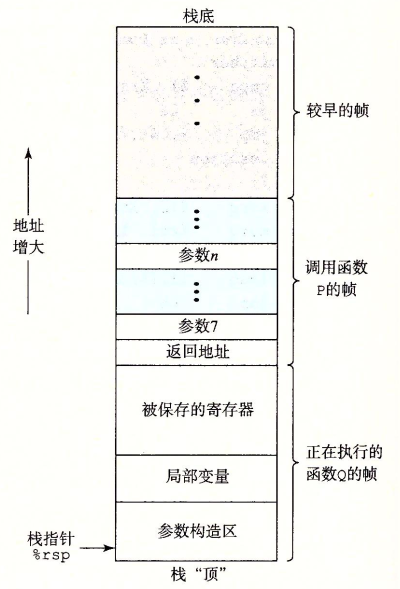
函数调用时,1 ~ 6 个参数是通过寄存器传递,7 个之后就需要借助函数栈了:

栈上的局部存储
函数内局部变量过多,无法都存储于寄存器中,所以需要存在栈内存中,即图中局部变量所示:

函数要通过引用类型返回多个值:

寄存器其实是被所有调用的函数共享的资源,rbp、rbx、r12~r15这几个寄存器被划分为 被调用者保存寄存器, 当 P 调用 Q 时,Q 必须保证这些寄存器的值在调用前 与 调用后不变,所以如果本函数中要使用这几个寄存器,就一定要进行入栈PUSH和出栈POP操作,并且要注意顺序:
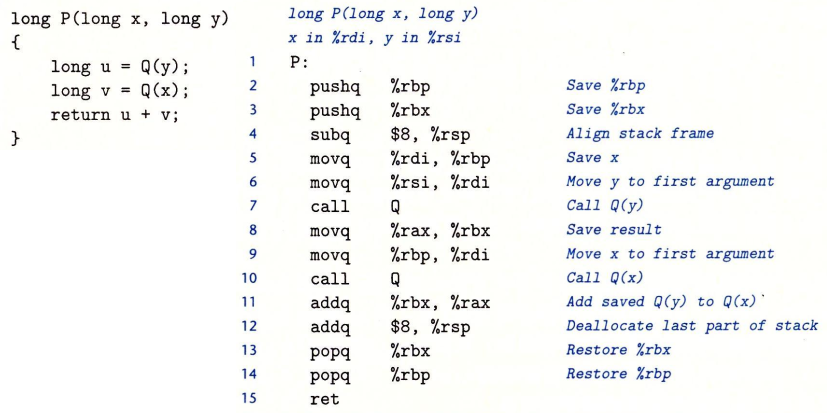
栈提供了一种机制,每次函数调用都有它自己的私有状态信息(保存的返回位置、被调用者保存寄存器的值、局部变量),递归调用一个函数本身,与调用一个别的函数并无不同:

C 语言数据存储
数组
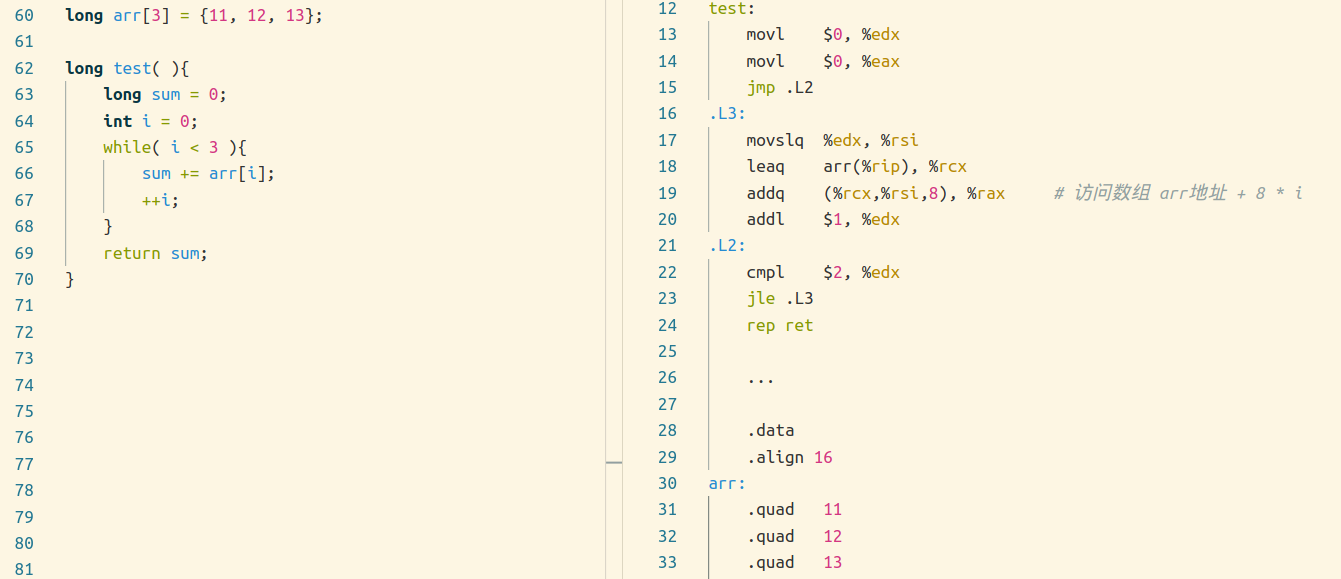
结构体
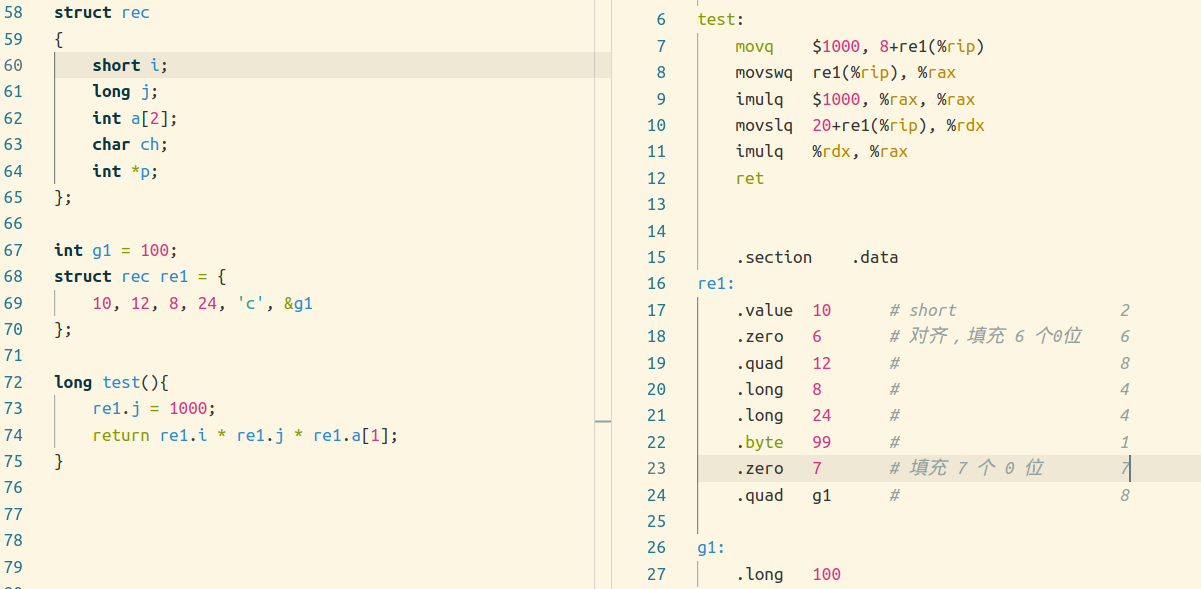
其实数组和结构体最重要的一点都是,数据元素的起始地址,数组的话还有到下一个元素地址的计算。
变长栈帧
leave指令相当于下面两条指令:

使用变长栈帧实现变长数组的原理例子:
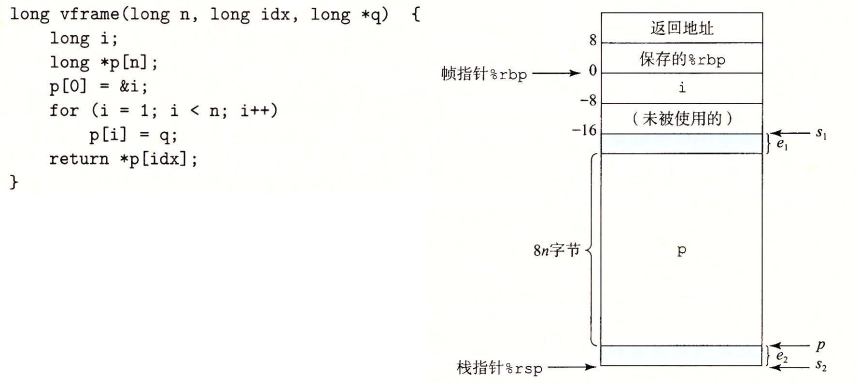

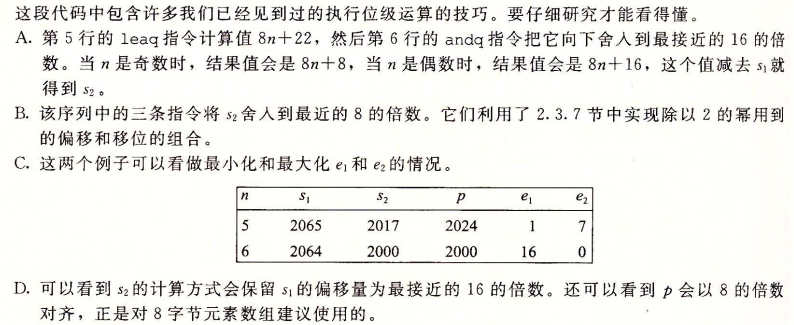

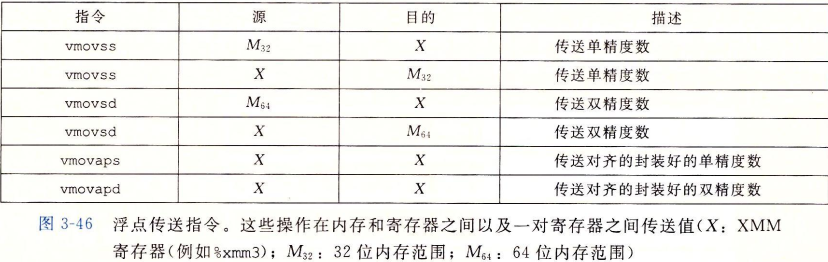
浮点数指令
浮点数寄存器有: ymm0 ~ ymm15 xmm0 ~ xmm15 共 32 个,其中xmm0 用于函数返回值 和 函数第一个参数, xmm1 ~ xmm7 用于第 2 ~ 8 个函数参数,xmm8 ~ xmm15 是调用者保存。

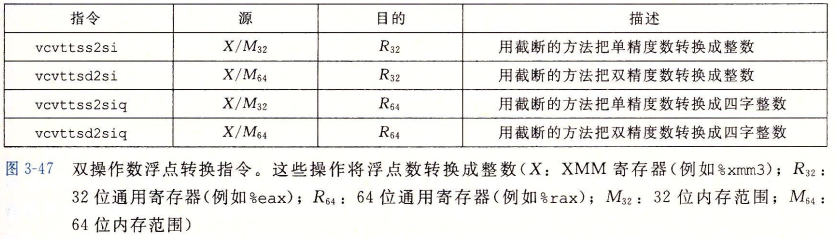
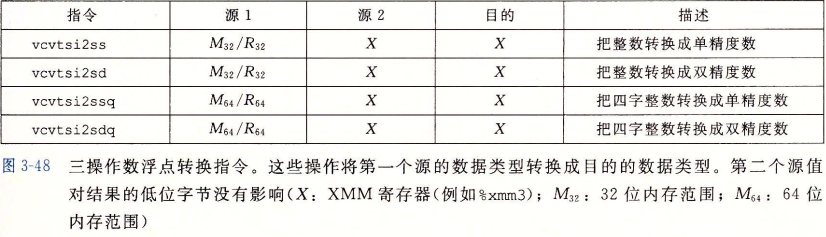



insight 调试器
安装: Ubuntu 16.04 安装 Insight 实现汇编的调试
寄存器

64 位寄存器:
1F : eflags
2I : rdi(字符串操作的 dest index) rsi(字符串操作的 src index)
3P : rbp(一般指向栈中数据) rip(程序计数器PC) rsp(指向栈顶)
4X : rax(用于返回值) rbx(用于指向数据段数据) rcx(用于循环计数) rdx(I/O pointer)
8R : r8, r9, r10, r11, r12, r13, r14, r15
6S : CS, DS, ES, SS, FS, GS 段寄存器,一般64位下汇编程序,不再操作这几个了
标志寄存器 Eflags

| 标志位 | 名称 | 作用 |
|---|---|---|
CF Carry Flag | 进位标志 | 运算结果产生进位 |
ZF Zero Flag | 零标志 | 指令结果为 0 |
SF Sign Flag | 负数标志 | 运算结果为 负数 |
OF Overflow Flag | 溢出标志 | 有符号加减 溢出 |
TF Trap flag | 单步调试标志 | 设置后,每执行一条指令,产生一个单步中断 |
IF Interrupt-enable Flag | 中断屏蔽标志 | 设置IF = 0 CPU 屏蔽部分中断(包括单步中断) |
PF Parity Flag | 奇偶标志 | 运算结果中 1 的个数为偶数 |
AF Auxiliary Carry Flag | 辅助进位标志 | 发生低字节向高字节进位/借位 |
VM Virtual Model | 虚拟 8086 模式标志 | 设置后,CPU 处于虚拟 8086 方式下工作 |
AC Alignment Check | 对齐标志 | 如果没在边界寻找一个字或者双字 则会设置该标志 |
RF Restart Flag | 重启标志 | |
VIF Virtual Interrupt Flag | 虚拟IF | Pentium 之后处理器有效 |
VIP Virtual Interrupt Pause | 虚拟中断标志 | 在多任务环境下,给操作系统提供虚拟中断标志和中断暂挂信息 |
以及只有在 32 位以上才可以使用的:
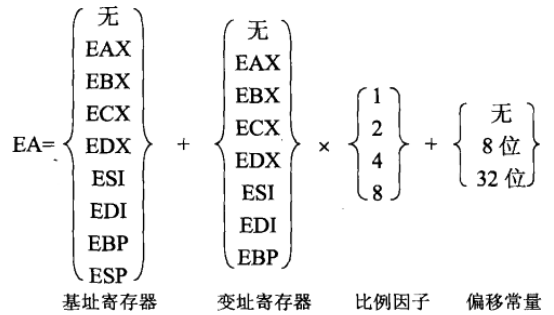
mov eax, [ebx+ebp] ; 默认段寄存器 DS
mov edx, ES:[eax*4 + 200H] ; 指定段寄存器为 ES
mov [esp + edx*2],eax ; 默认 SS
mov ebx,GS:[eax + edx*2 + 300H] ; 指定 GS
mov ax,[esp] ; 默认 SS操作符和变量
在高级语言中,要表达一个变化的值,需要一个具有某种数据类型的变量,该变量的名字称为标识符。汇编语言里面也类似,只是符号名的说明和引用方式不同而已。
定义变量
格式:
[变量名] 数据定义符 表达式1,表达式2,...数据定义符号包括: db定义字节、 dw定义字、 dd定义双字、 dq定义 8 个字节
counter db 6
db 'A','D',0DH,'$'
msg db "i am a student"
myword dw 89H, 1909H, -1
dw 0ABCDH, 0
mydword dq 012345678H, 0H, -1234H
dq 1238HC 与 汇编
空函数
long empty_func()
{
}empty_func:
push rbp ; 保护现场,保存调用方的栈基
mov rbp, rsp ; 将 新栈顶 作为本函数的栈基
nop ; 因为是空函数,所以什么也不做
pop rbp ; 恢复现场, 恢复调用方的栈基
ret带有返回值的函数
long return_func()
{
return 42;
}return_func:
push rbp
mov rbp, rsp
mov eax, 42 ; 函数的返回值放在 eax
pop rbp
ret函数传值
long return_func( long a , long b )
{
return a;
}
int main(){
return_func( 20, 30 );
return 0;
}
return_func:
push rbp
mov rbp, rsp
mov QWORD PTR -8[rbp], rdi ; 将局部变量 a 放在 (当前栈基 - 8) 地址处
mov QWORD PTR -16[rbp], rsi ; 将局部变量 b 放在 (当前栈基 -16) 地址处
mov rax, QWORD PTR -8[rbp] ; 再将 a 的值,移入 rax
pop rbp
ret
main:
...
mov esi, 30
mov edi, 20
call return_func
...函数传非常多个值
long multi_parm( long a , long b, long c, long d, long e, long f, long g, long h, long i )
{
return g + h + i;
}对于 6 个以内的传值(包括指针),依次使用rdi rsi rdx rcx r8 r9传值,多于 6 个的话, 则直接使用 调用方 的栈来操作。
multi_parm:
push rbp
mov rbp, rsp
mov QWORD PTR -8[rbp], rdi ;a
mov QWORD PTR -16[rbp], rsi ;b
mov QWORD PTR -24[rbp], rdx ;c
mov QWORD PTR -32[rbp], rcx ;d
mov QWORD PTR -40[rbp], r8 ;e
mov QWORD PTR -48[rbp], r9 ;f
mov rdx, QWORD PTR 16[rbp] ;g , 16[rbp] 这个计算后就是调用方的栈地址
mov rax, QWORD PTR 24[rbp] ;h
add rdx, rax
mov rax, QWORD PTR 32[rbp] ;i
add rax, rdx
pop rbp
ret总结下函数调用栈的主要功能:
保存 调用方(上层函数) 的调用状态(保存现场 + 恢复现场操作)
保存当前函数的局部变量
为下层函数调用做参数准备(当参数多于 6 个时)
函数调用方式:
普通调用
call和retcall和ret加enter和leaveenter和leave可以用来辅助设置和清理调用栈
系统调用
通过
int 0x80中断sysenter和sysexitsyscall和sysret
Near Call : 调用函数在当前代码段,一般一个进程内的函数都在一个代码段内。
Far Call : 调用函数在其他代码段,一般用于系统调用 或 调用其他进程内的函数。
HelloWorld 例子
; test.s 例子
global _start
section .data
hello : db `hello, world!\n`
section .text
_start:
mov rax, 1 ; system call number should be stored in rax
mov rdi, 1 ; argument #1 in rdi: where to write (descriptor)?
mov rsi, hello ; argument 2 in rsi: where does the string start?
mov rdx, 14 ; argument #3 in rdx: how many bytes to write?
syscall ; this instruction invokes a system call
mov rax, 60 ; 'exit' syscall number
xor rdi, rdi
syscall$ nasm -g -f elf64 -F dwarf test.s -o test.o # 编译
$ objdump -d -M intel test.o # 查看生成的目标文件,可以观察到,没有给程序的入口分配地址
0000000000000000 <_start>:
0: b8 01 00 00 00 mov eax,0x1
5: bf 01 00 00 00 mov edi,0x1
a: 48 be 00 00 00 00 00 movabs rsi,0x0
...$ ld test.o -o test # 链接
$ objdump -d -M intel test # 链接后,就有程序入口地址了,可以执行它了
00000000004000b0 <_start>:
4000b0: b8 01 00 00 00 mov eax,0x1
4000b5: bf 01 00 00 00 mov edi,0x1
4000ba: 48 be d8 00 60 00 00 movabs rsi,0x6000d8
...
$ ./test # 执行
hello, world!